下载器中间件middleware主要有两个类
1 | process_request(spider,request) |
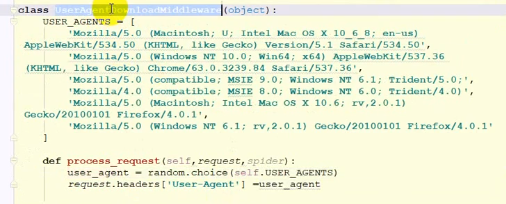
使用随机请求头请求url
使用随机ip代理
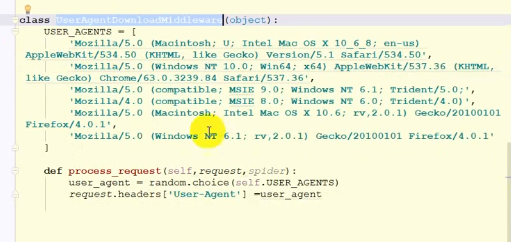
使用独享代理ip访问
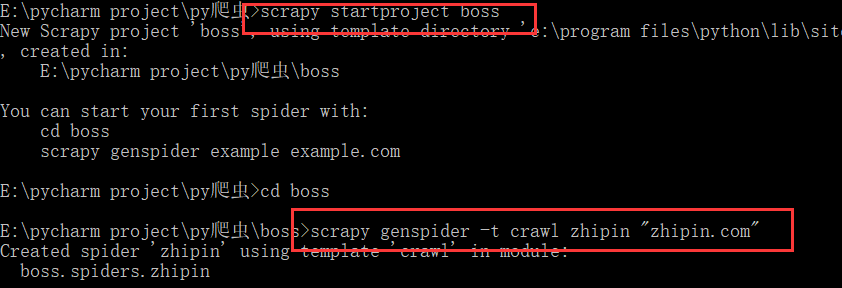
创建爬取boss直聘网的项目使用crawl模板
全站爬取简书网
爬取规则
1 | rules = ( |
采用scrapy shell 检验我们的xpath语法是否准确
1 | # 进入项目根目录 |
用xpath解析页面
1 | In [3]: title = response.xpath("//h1[@class='_1RuRku']//text()").get() |
采用selenium和webdriver和scrapy和mysql的方式爬取信息
项目结构
jianshu.py
1 | # -*- coding: utf-8 -*- |
items
1 | # -*- coding: utf-8 -*- |
middlewares.py 中间件
1 | # -*- coding: utf-8 -*- |
pipelines.py 下载器,采用我们自己写的下载器
1 | class JianshuTwistedPipeline(object): |


